Firecrawl Integration
Firecrawl is a powerful web scraping and crawling tool that allows you to extract structured data from websites. This integration provides two main functionalities for comprehensive web data extraction.Overview
The Firecrawl integration consists of two specialized tools designed for different web scraping needs:FirecrawlScrape
Extract data from a single webpage with support for multiple formats,
structured extraction, and AI-powered content analysis.
FirecrawlCrawl
Recursively crawl and scrape multiple pages from a website with advanced
filtering and rate limiting options.
Key Features
🎯 Flexible Data Extraction
- Multiple output formats: Markdown, HTML, JSON, Screenshots, Links
- AI-powered content extraction using natural language prompts
- Schema-based structured data extraction
🔧 Advanced Configuration
- Customizable crawling depth and limits
- Path filtering with include/exclude patterns
- Rate limiting and concurrency controls
📸 Visual Content Capture
- Standard and full-page screenshots
- Base64 encoded image output
- Perfect for visual documentation and monitoring
🧠 AI-Enhanced Extraction
- Natural language prompts for flexible data extraction
- Structured schemas for precise data collection
- Intelligent content parsing and organization
Authentication
Before using any Firecrawl tools, you need to obtain an API key from Firecrawl and configure it in your application.
Step 1: Get Your API Key
First, sign up for a Firecrawl account and obtain your API key from the dashboard.Step 2: Configure Authentication in UI
To set up Firecrawl authentication in the application interface:- Navigate to the Tools section in your agent configuration
- Select Firecrawl from the available tools
- Enter your API key in the authentication field
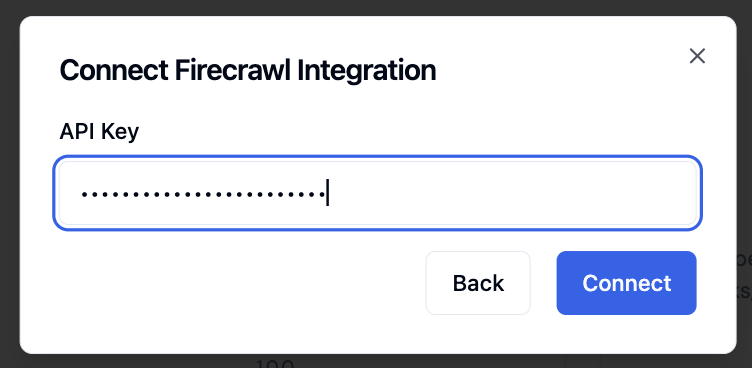
Step 3: Verify Connection
Once configured, the system will validate your API key and display a connection status indicator.📊 Content Analysis & Research
- Extract articles, blog posts, and documentation
- Gather competitive intelligence
- Monitor website changes and updates
🏢 Lead Generation & Business Intelligence
- Extract company information and contact details
- Analyze product catalogs and pricing
- Monitor competitor websites
📱 Web Monitoring & Testing
- Take screenshots for visual regression testing
- Monitor website availability and content changes
- Extract structured data for analysis
🔍 SEO & Marketing
- Analyze meta tags, keywords, and content structure
- Extract social media links and contact information
- Monitor backlinks and site structure
Response Format
Both tools return data in a consistent format:Error Handling
Both tools provide comprehensive error information:- Invalid URL format
- Network connectivity issues
- Rate limiting exceeded
- Invalid API key
- Target website blocking requests
Best Practices
🚀 Performance Optimization
- Use appropriate limits to avoid excessive resource usage
- Implement delays for rate limiting when crawling
- Filter paths to focus on relevant content
- Monitor crawling depth to prevent infinite loops
🔒 Ethical Scraping
- Always respect websites’ robots.txt files
- Implement appropriate delays between requests
- Avoid overwhelming target servers
- Comply with website terms of service
💡 Efficient Data Extraction
- Use schema-based extraction for structured data
- Combine multiple formats when needed
- Leverage AI prompts for flexible content extraction
- Cache results when appropriate
Credits and Billing
Firecrawl operates on a credit-based system. Each operation consumes credits based on:- Number of pages processed
- Amount of content extracted
- Additional features used (screenshots, structured extraction)
Next Steps
Learn Scraping
Get started with single-page data extraction
Learn Crawling
Explore multi-page website crawling
For more advanced features and API documentation, visit the official Firecrawl documentation.