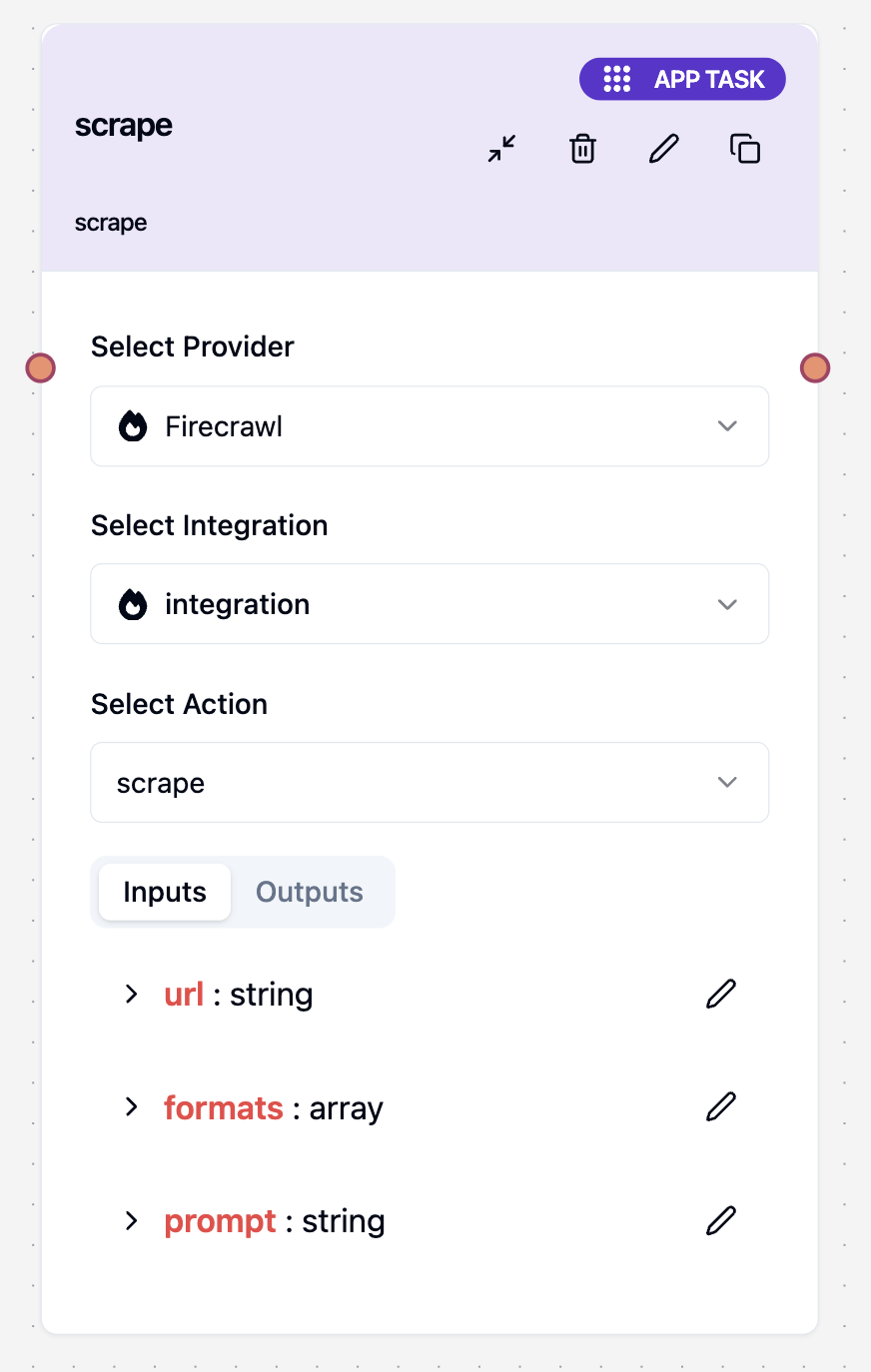
FirecrawlScrape
The FirecrawlScrape tool extracts data from a single webpage and supports multiple output formats including markdown, HTML, JSON, screenshots, and AI-powered structured data extraction.Overview
FirecrawlScrape is perfect for extracting content from individual web pages with precision and flexibility. Whether you need clean markdown content, structured data, or visual screenshots, this tool provides comprehensive extraction capabilities.Input Parameters
| Parameter | Type | Required | Default | Description |
|---|---|---|---|---|
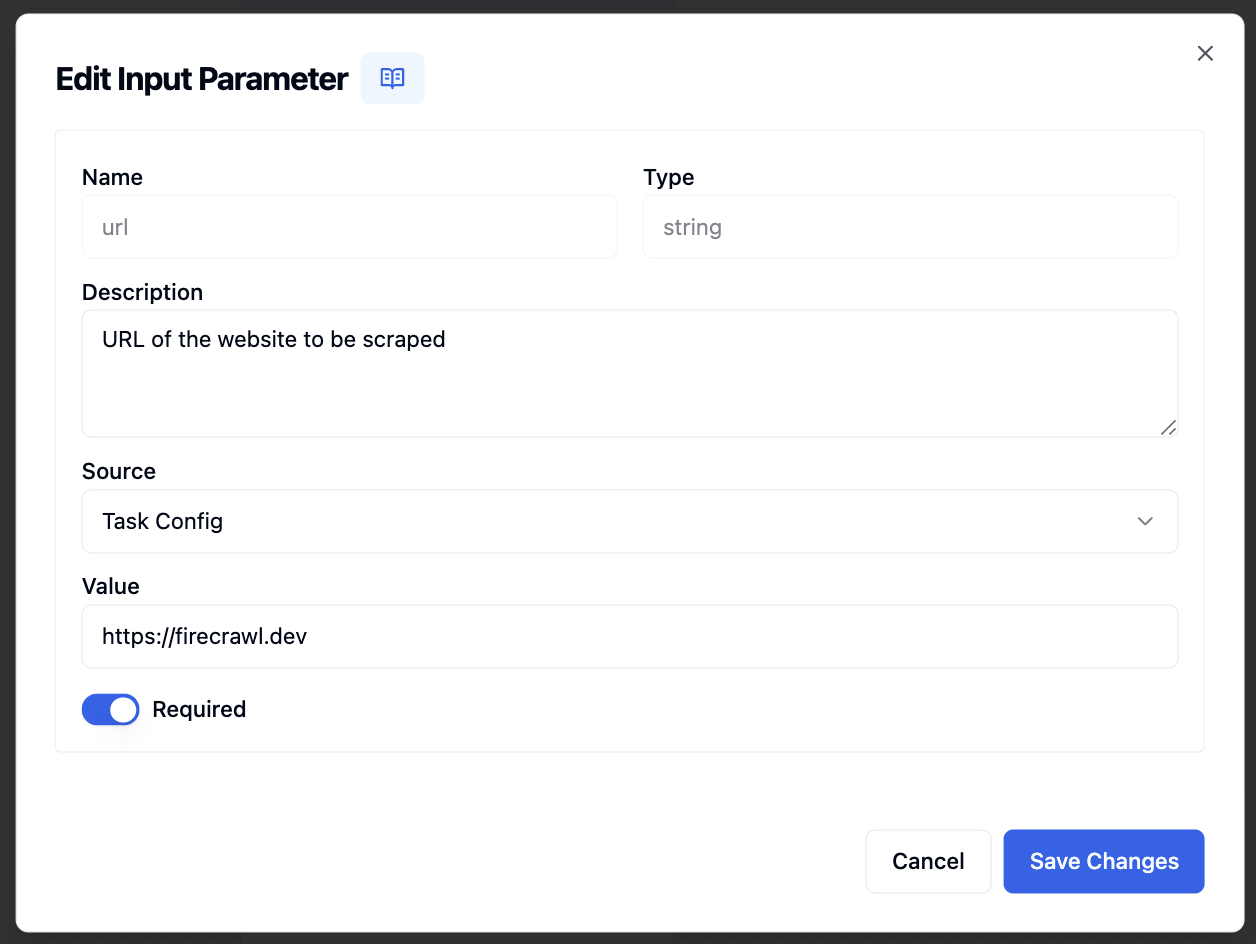
url | string | Yes | - | URL of the website to be scraped |
formats | string[] | Yes | ["markdown", "html"] | List of content formats to extract. Valid values: "markdown", "html", "json", "links", "screenshot", "screenshot@fullPage", "rawHtml" |
prompt | string | No | - | A natural language instruction used for schema-less extraction. The LLM will interpret the prompt and return relevant structured data from the page |
schema | object | No | - | A JSON schema that defines the structure and data types to extract from the webpage for precise, structured extraction |
Available Formats
Theformats parameter accepts the following values:
Content Formats
"markdown"- Clean markdown representation of the page content"html"- Cleaned and formatted HTML content"rawHtml"- Complete raw HTML source code"json"- Structured JSON data (used with schemas or prompts)
Link and Media Formats
"links"- All links found on the page"screenshot"- Screenshot of the visible page area"screenshot@fullPage"- Full-page screenshot including content below the fold
Basic Usage
Simple Content Extraction
To extract basic content from a webpage:- Enter the URL: Input the target webpage URL in the URL field
- Select Formats: Choose the desired output formats (markdown, HTML, etc.)
- Run the Task: Execute the scraping operation
- URL:
https://example.com - Formats:
["markdown", "html", "links"]
Schema-Based Structured Extraction
Define a precise schema for structured data extraction to get specific information in a predictable format.How to Configure Schema Extraction
- Add JSON Format: Include
"json"in your formats selection - Define Schema: Specify the data structure you want to extract
- Set Data Types: Use appropriate types (string, number, boolean, array, object)
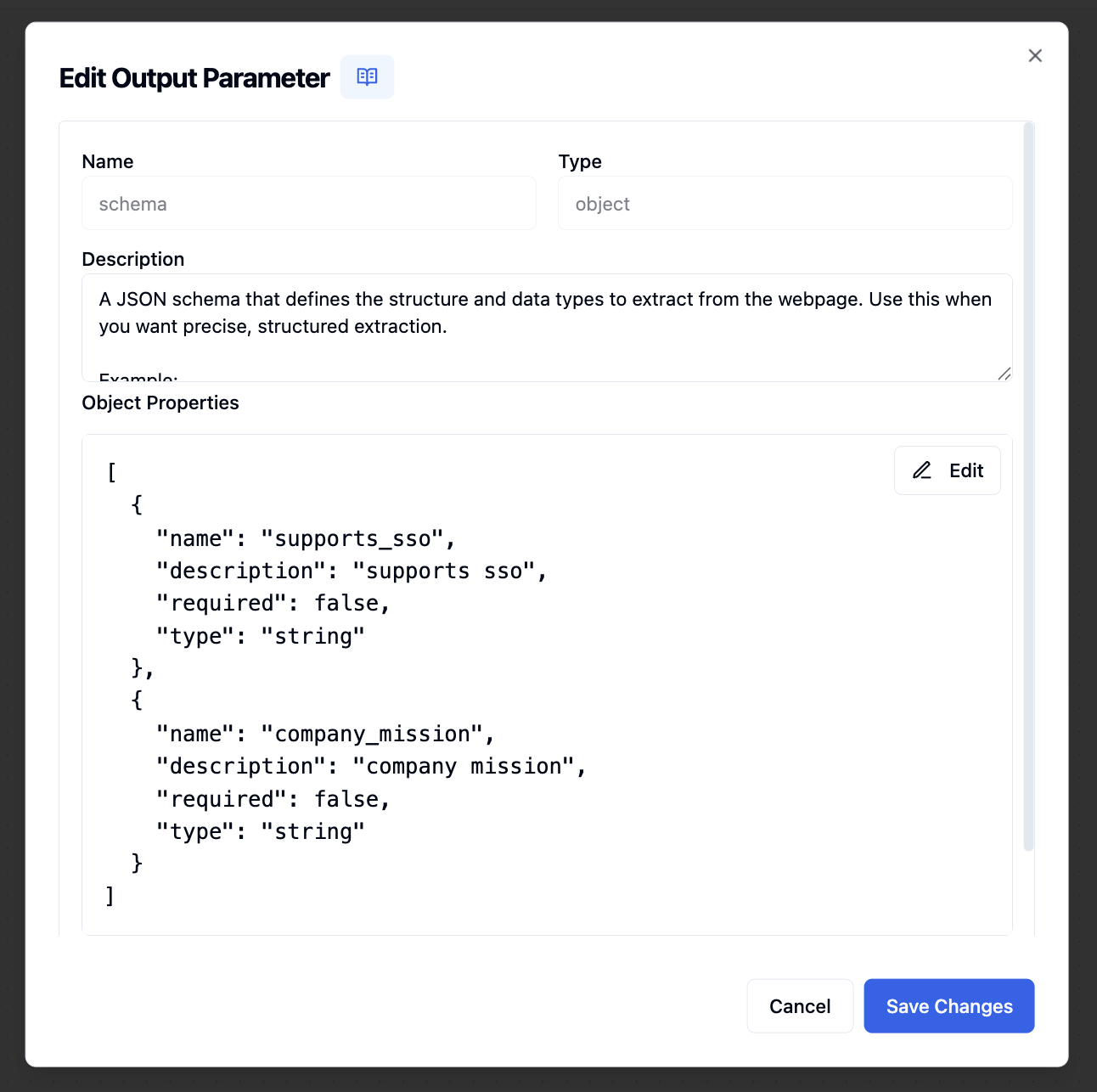
When using schema-based extraction, make sure to include
"json" in the
formats array. The schema defines the exact structure and data types you want
to extract from the webpage.Advanced Schema Examples
Product Information Extraction
Company Information Extraction
Prompt-Based Extraction
For flexible data extraction without predefined schemas, use natural language prompts to describe what information you want to extract.How to Configure Prompt Extraction
- Add JSON Format: Include
"json"in your formats selection - Write Clear Prompt: Describe what information you want to extract
- Be Specific: The more specific your prompt, the better the results
Effective Prompt Examples
Content Analysis
Contact Information
Product Features
Response Format
Use Cases
📊 Content Extraction
Extract blog posts, articles, and documentation:- URL:
https://blog.example.com/latest-post - Formats:
["markdown", "json"] - Schema:
🏢 Business Information
Extract company details and information:- URL:
https://company.com/about - Formats:
["json"] - Prompt:
"Extract company name, mission, team size, contact information, and key services offered"
🛍️ Product Analysis
Extract product information from e-commerce sites:- URL:
https://store.com/product/123 - Formats:
["json", "screenshot"] - Schema:
📸 Visual Documentation
Capture page screenshots and structure:- URL:
https://example.com - Formats:
["screenshot@fullPage", "links", "markdown"]
Best Practices
⚡ Performance Tips
-
Choose Appropriate Formats
- Only request formats you actually need
- Use
"screenshot"instead of"screenshot@fullPage"for large pages
-
Use Specific Schemas
- Define precise data structures for better accuracy
- Use appropriate data types (number, boolean, array)
-
Craft Clear Prompts
- Be specific about what information you want
- Avoid overly broad or vague instructions
🎯 Extraction Accuracy
-
URL Format
- ✅ Always include the protocol:
https://example.com - ❌ Avoid incomplete URLs:
example.com
- ✅ Always include the protocol:
-
Schema Data Types
- ✅ Use
"number"for numerical data - ✅ Use
"boolean"for true/false values - ✅ Use
"array"for lists
- ✅ Use
-
Format Selection
- ✅ Always specify required formats
- ❌ Don’t leave formats empty
Common Issues and Solutions
URL Format Errors
- Problem: Missing protocol in URL
- Solution: Always include
https://orhttp://
Missing Required Formats
- Problem: No formats selected
- Solution: Always specify at least one output format
Schema Type Mismatches
- Problem: Using wrong data types in schema
- Solution: Match data types to expected content (string, number, boolean, array)
Poor Extraction Results
- Problem: Vague prompts or overly complex schemas
- Solution: Be specific and clear in prompts, keep schemas focused
Next: Learn Crawling
Explore multi-page website crawling with FirecrawlCrawl